
티스토리 뷰
배치 프로그램 및 Spring batch , JpaItemReader, MongoItemReader 활용
dev ms 2016. 5. 11. 18:00배치 프로그램
정의 :
일반적으로 배치(Batch) 프로그램이라 하면, 일련의 작업들을 하나의 작업 단위로 묶어 연속적으로 일괄 처리하는 것을 말한다. 온라인 프로그램에서도 여러 작업을 묶어 처리하는 경우가 있으므로 이와 구분하려면 한 가지 특징을 더 추가해야 하는데, 사용자와의 상호작용(Interaction) 여부다.
사용자와의 상호작용 없이
대량의 데이터를 처리하는
일련의 작업들을 묶어
정기적으로 반복 수행하거나
정해진 규칙에 따라 자동으로 수행
종류
정기 배치 : 정해진 시점(주로 야간)에 실행
이벤트성 배치 : 사전에 정의해 둔 조건이 충족되면 자동으로 실행
On-Demand 배치 : 사용자의 명시적인 요구가 있을 때마다 실행
배치 환경의 변화
과거 :
일(Daily) 또는 월(Monthly) 배치 작업 위주- 야간에 생성된 데이터를 주간 업무시간에 활용- 온라인과 배치 프로그램의 구분이 비교적 명확
현재 :
시간(Hourly) 배치 작업의 비중이 증가- 분(minutely) 배치 작업이 일부 존재- On-Demand 배치를 제한적이나마 허용
하지만 시간 배치 작업을 본인은 하지 않았다.
월배치나 일배치로 하는 작업을 수행.
회원 랭킹 및 탈퇴 회원 계정 삭제 등에 쓰임.
이전에 회원 단체 SMS 발송도 Web Application에 있었는데 Batch 프로젝트로 작성했으면 좋았을 거라고 생각함.
배치 목표에 따라 성능개선이 틀려진다.
온라인 프로그램은 경우에 따라 전체 처리속도 최적화나 최초 응답속도 최적화를 목표로 선택하지만,
배치 프로그램은 항상 전체 처리속도 최적화를 목표로 설정해야 한다.
개별 프로그램 차원에서도 그렇지만 야간에 수행되는 전체 배치 프로그램에 대한 목표도 마찬가지다.
개별 서비스 또는 프로그램을 가장 빠른 속도로 최적화하더라도 전체 배치 프로그램 수행시간을 단축시키지 못하면 무의미하다.
여러 부서의 배치가 있다면 (그림과 같이 배치 윈도우를 구성) 서로 겹치지 않게 자원을 쓸수 있게 하면 시간을 단축 시킬 수 있다.
배치 성능이나 성공 실패 여부도 중요하다. 따라서 관련 내용을 어떻게 기록 할 것인가도 중요하게 생각해야 한다.
배치 프로그램이 적절하게 잘 작동하는지 모니터링 시스템이 있어야 정확하게 확인 할 수 있기 때문이다.
그래서 본인은 스프링 Batch를 사용하였다. (물론 내가 도입하자고 한건 아니다. 기존에 구현된 배치 프로그램이 스프링으로 구현되어있있고, 그 스프링 배치가 관리를 해준다는 것을 알게 된 것 이다.)
그 밖에 내용은 아래 링크를 통해 확인하면 될 것 같다.
매우 low레벨까지 설명하고 있는 듯 하다.
출처 :
http://wiki.gurubee.net/pages/viewpage.action?pageId=26746011
스프링 배치
1.1 스프링 배치 기능
Job Repository 를 통한 배치 모니터링
배치에 적합한 트랜잭션 처리를 위해 주기적인 commit방식 지원.
배치작업의 재시도, 재시작, 건너뛰기 등의 정책을 설정으로 적용할 수 있다.
Commit 개수, Rollback 개수, 재시도 횟수 등 배치실행 통계 정보를 제공한다.
다양한 실행 방법 지원 - Quartz, CommandLine, JMX콘솔, OSGi, 동기/비동기-병렬 실행 ...
스프링 배치 구성요소

용어 정의
JobLauncher
JobLauncher는 배치 Job을 실행시키는 역할을 한다.
Job과 Parameter를 받아서 실행. JobExecution를 반환 함.
Job
실행시킬 작업을 의미, 논리적인 잡 실행의 개념, job configuration과 대응되는 단위.
JobParameter
배치잡을 시작하는데 사용하는 파라미터의 집합으로 잡이 실행되는 동안에 잡을 식별하거나 잡에서 참조하는 데이터로 사용.
JobInstance
논리적인 Job 실행
JobInstance=Job+JobParameter
JobExecution
단 한 번 시도되는 Job 실행을 의미하는 기술적인 개념
시작시간, 종료시간 ,상태(시작됨,완료,실패),종료상태의 속성을 가짐
JobRepository
수행되는 Job에 대한 정보를 담고 있는 저장소.
어떠한 Job이 언제 수행되었고, 언제 끝났으며, 몇 번이 실행되었고 실행에 대한 결과가 어떤지 등의 Batch수행과 관련된 모든 meta data가 저장되어 있다.
Step
Batch job을 구성하는 독립적인 하나의 단계
Job은 하나이상의 step으로 구성
실제 배치 처리 과정을 정의하고, 제어하는데 필요한 모든 정보를 포함
Step의 내용은 전적으로 개발자의 선택에 따라 구성됨.
Step Execution
하나의 step을 실행하는 한번의 시도.
시작시간, 종료시간,상태, 종료상태, commitCount, itemCount 의 속성을 가진다.
Item
처리할 데이터의 가장 작은 구성 요소.
(예)파일의 한 줄, DB의 한 Row, Xml의 특정 element )
ItemReader
Step안에서 File 또는 DB등에서 Item을 읽어 들인다
더 이상 읽어올 Item이 없을 때에는 read()메소드에서 null값을 반환. 그 전까지는 순차적인 값을 리턴
ItemWriter
Step안에서 File 또는 DB등으로 Item을 저장한다.
Item Processor
Item reader에서 읽어 들인 Item에 대하여 필요한 로직처리 작업을 수행한다.
Chunk
하나의 Transaction안에서 처리할 Item의 덩어리.
chunk size가 10이라면 하나의 transaction안에서 10개의 item에 대한 처리를 하고 commit을 하게 되는 것이다.
실제 개발을 할땐 -_-;; 해석된 내용을 찾지 못해 원문 spring 사이트의 설명을 대충 해석하고 구현 코드로 대충 개념을 이해했었다.
Job
Job은 배치작업 전체의 중심 개념으로 배치작업 자체를 의미한다. Job은 실제 프로세스가 진행되는 Step들을 최상단에서 포함하고 있으며, Job의 실행은 배치작업 전체의 실행을 의미한다.
JobInstance
JobInstance는 논리적 Job 실행의 개념으로 JobInstance = Job + JobParameters로 표현할 수 있다.
다시 말해, JobInstance는 동일한 Job이 각기 다른 JobParameter를 통해 실행 된 Job의 실행 단위이다. (Job과 JobParameters가 같으면 동일한 JobInstance이다.)
JobParameters
JobParameters는 하나의 Job에 존재할 수 있는 여러개의 JobInstance를 구별하기 위한 Parameter 집합이며, Job을 시작하는데 사용하는 Parameter 집합이다.
또한 Job이 실행되는 동안에 Job을 식별하거나 Job에서 참조하는 데이터로 사용된다. 위의 그림(JobInstance 부분)으로 예를들면 'EndOfDay' Job으로 2개의 JobInstance가 생성됐다. 이 2개의 JobInstance는 각기 다른 JobParameters('2012/10/01', '2012/10/02')를 통해 생성된 것이다.
필수 요소 및 JobIntance를 확인하길 바란다.
-_-;; 같은 파라미터를 보내면 fail Error가 발생했었는데 그 이유가 자세히 설명되어 있다..
http://www.egovframe.go.kr/wiki/doku.php?id=egovframework:rte2:brte:batch_core:job
위에 나열된 단어 및 그림으로 확인 할 수 있듯이.
1개의 배치작업은 Job 의 단위로 볼 수 있고,
Job을 구성하는 요소는 여러개의 Step으로 구성된 것을 알 수 있다.
그리고 각 Step 안에는 ItemReader, ItemProcess, ItemWriter 등으로 구성되어있다.
배치 프로그램은 대용량 데이터 처리를 목적으로 하기 때문에, 한꺼번에 처리할려고 하면 시스템에 많은 부하가 갈 수 있다. 따라서 Spring 배치를 이용하여 chunk 단위로 나뉘어 작업할 수 있다.
사내에 구현된 기존 시스템은 row 레벨 작성되어 있었고, 직접 데이터를 페이징을 하여 처리하는 방식으로 개발이 되어있었다.
Spring batch의 내용을 보면 Step에서 chunk 단위로 처리가 가능한 것을 확인 할 수 있다.
Chunk 기반 처리(Chunk-Oriented Processing)
Chunk 기반 처리는 스프링 배치에서 가장 일반적으로 사용하는 Step 유형이다. Chunk 기반 처리는 data를 한번에 하나씩 읽고, 트랜잭션 범위 내에서 'Chunk'를 만든 후 한번에 쓰는 방식이다.
즉, 하나의 item이 ItemReader를 통해 읽히고, Chunk 단위로 묶인 item들이 한번에 ItemWriter로 전달 되어 쓰이게 된다.
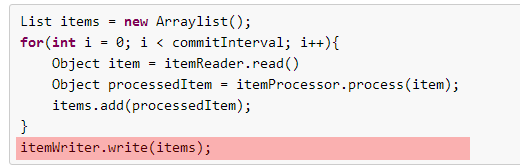
Chunk 단위로 Item 읽기 → 처리/변환 → 쓰기의 단계를 거치는 Chunk 기반 처리 매커니즘은 다음과 같다
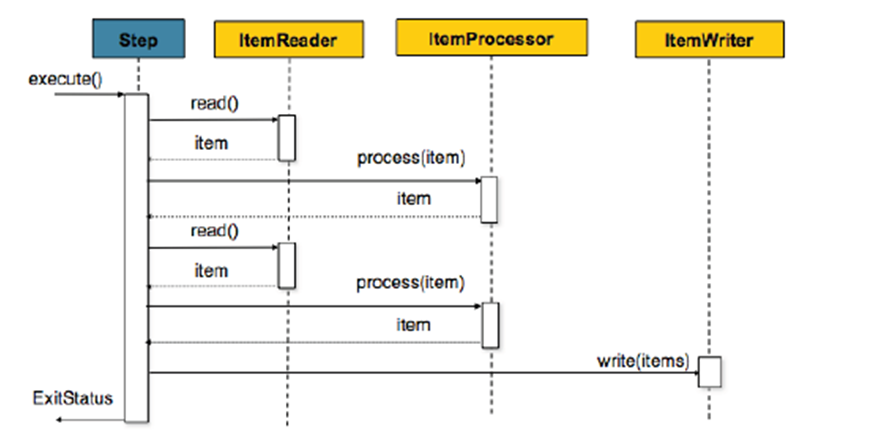

예제 코드 에서 보는 것과 같이 itemReader는 각 데이터를 읽는 부분이고
process 는 itemReader에서 읽어들인 data 1개를 처리하는 방식으로 진행 된 뒤
writer에서 DB에 씌어진다.
TaskletStep
배치작업을 적용한 업무 환경에 따라 ItemReader와 ItemWriter를 활용한 구조가 맞지 않는 경우도 있을 것이다.
예를들어 단순히 DB의 프로시저 호출만으로 끝나는 배치처리가 있다면 단순히 메소드 하나로 기능을 구현하고 싶어질 것이다. 이런 경우를 위해 스프링 배치에서는 TaskletStep을 제공한다.
Tasklet은 RepeatStatus.FINISHED를 반환하거나 에러가 발생하기 전까지 계속 실행하는 execute() 하나의 메소드를 갖는 간단한 인터페이스로 저장 프로시저, 스크립트, 또는 간단한 SQL 업데이트 문을 호출 할 수 있다.
TaskletStep을 구성하기 위해서는 <tasklet> 태그의 'ref'속성을 통해 Tasklet 객체를 참조해야한다. <chunk> 태그는 <tasklet> 내에서 사용되지 않는다.(<Chunk> 태그는 Chunk-Oriented Processing에서 사용된다.)
기존에 row 레벨로 되어있다는 것이 tasklet으로 구현되어 있었고, 그 자체 안에서 paging이 구현되어 데이터를 나눠서 처리하는 방식으로 되어 있었다.
위 Step에서의 chunk 단위로 작업을 실행하면 별도의 작업 없이 가능했던 부분이다.
StepExecution
Job의 JobExecution과 대응되는 단위로 Step 또한 StepExecution을 갖고 있다.
JobExecution과 마찬가지로 StepExecution은 Step을 수행하기 위한 단 한번의 Step 시도를 의미하며 매번 시도될 떄마다 생성된다.
또한, StepExecution은 주로 Step이 실행 중에 어떤 일이 일어났는지에 대한 속성들을 저장하는 저장 메커니즘 역할을 하며 commit count, rollback count, start time, end time 등의 Step 상태정보를 저장한다. (StepExecution 속성 자세히 보기)
아래의 그림에서 'Step1', 'Step2' 2개의 Step을 갖는 'EndOfDay' Job이 두번 실행되었다고 가정하자.(두번 시도 결과 JobExecution은 2개 생성) 'EndOfDay' Job을 시도할 때마다 'Step1', 'Step2'도 시도 되기때문에 StepExecution은 2개 씩 생성된다. 그래서 총 4개의 StepExecution이 생성된 것을 볼 수 있다.
이걸 -_- Exception 처리 하는 구문으로 알아봤었다 ..
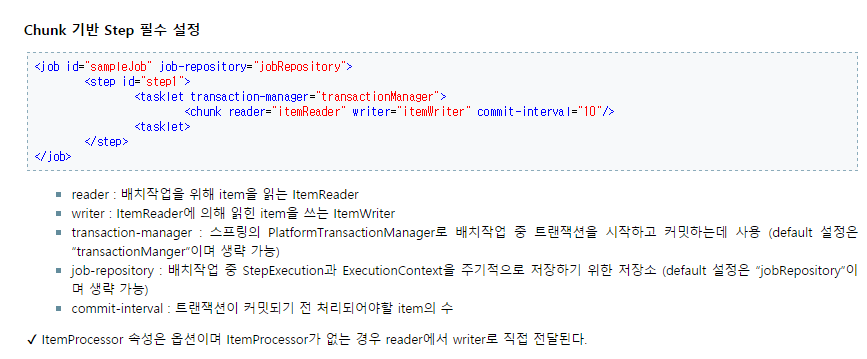
그 밖의 설정에 대해서는 아래 링크를 확인하길 바란다.
http://www.egovframe.go.kr/wiki/doku.php?id=egovframework:rte2:brte:batch_core:step
스프링 배치 예제
내가 했던 배치 프로그램은 Spring boot , JPA, MongoDB 등을 이용하여 작성했다.
itemReader 의 종류는 아래 링크에 있고, JPA를 사용하였기 때문에 JpaPagingItemReader 를 사용하였다.
mongoDB에서는 마찬가지로 MongoItemReader 를 사용하여 작성하였다.
JpaPagingItemReader 예제
배치 프로세스는 병렬 처리 및 순차적으로 작성이 가능하다.

병렬 처리 방식을 사용하려면 Job을 정의할때 Step부분을 flow로 해서 작성하면 병렬로 처리 되고 아래와 같이 start로 작성하게 되면 순차적으로 처리가 가능하다.

그 뒤에 다음번 배치 프로세스를 등록한다면

.next를 이용해서 작성할 수 있다.
Step 작성

step을 작성할 땐 Input, Output을 정의하고 chunk 사이즈를 정의할 수 있다.
chunck 사이즈는 처리될 데이터의 단위이고, transaction의 범위라고 생각하면 된다.
Input, Output은 itemReader에서 읽을때 Input되는 데이터 형식과 Process에서 Input Object 형태로 받은 형식을 Output 형식으로 내보낸다고 정의 하는 것과 같다.
또는 Writer에서 매개변수로 전달 받는 Object Type이라고 생각하면 된다.
따라서 1개의 step에는 itemReader, process, itemWriter 로 작성되며

이런 형태로 처리가 된다고 이해하면 된다.
ItemReader

jpaPagingItemRader를 이용할땐 native Query가 작성되어져야 했다. 실제로 클래스를 열어보면 native 쿼리가 null이면 에러가 난다.
따라서 위 예제와 같이 작성하고, 추가적으로 파라미터가 있을 때는 다음과 같이 활용하면 된다.
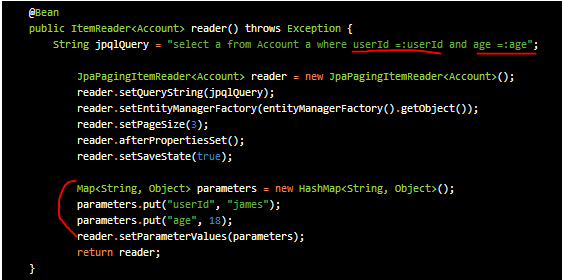

추가적으로 ItemReader로 JobParameter를 받기 위해서는 @StepScope 애노테이션을 이용해야 한다.

MongoItemReader
mongoDB를 사용하게되면 Batch 작성시 MongoItemReader를 사용하게 된다.
MongoItemReader를 열어보면
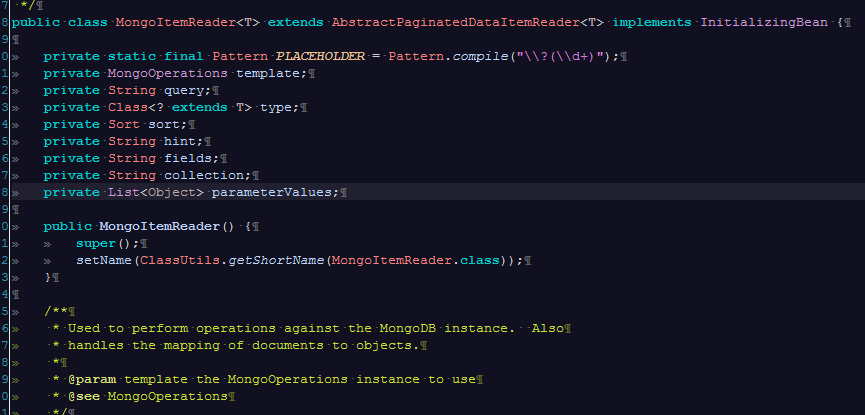
MongoOperations 을 이용하여 쿼리를 작성할 수 있고 이곳에서도 역시 query는 not null이다.
MongoOperation을 이용하여 aggregate등 복잡한 쿼리를 이용할 수도 있다.
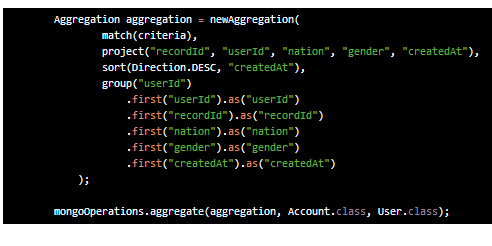
그리고 기본 where 조건도 operation을 이용해서 작성 할 수 있으며, 다른 쿼리가 없을땐 {}을 넣어준다.
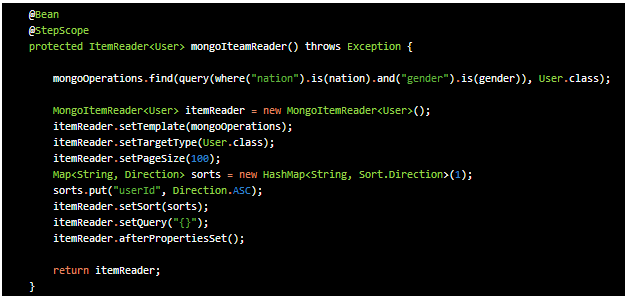
setParameters 부분도 있지만 어떻게 바인딩 시키는지는 따로 찾을 수가 없었고, 시도 해보았지만 계속 에러가 났다. 따라서 setQuery부분에 “{userId : 값}” 이런 형식으로 파라미터를 대입하는 방법으로 개발해야 될 것 같다.
그 밖의 writer나 process 부분은 동일하다.
ItemProcess
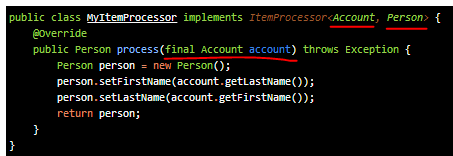
itemProcess는 itemReader에서 읽어들인 data를 가공하는 부분으로 ItemProcessor를 상속받아 작성한다. 여기서 Input, Output은 Step에서 정의한 것과 마찬가지로 작성해야 하며, Override 된 process 메서드에서 Input으로 선언한 Object를 매개변수로 받게 된다.
배치 프로세스를 돌려서 처리할 내용을 여기서 작성해주고 Output Object에 맞게 셋팅 후 return 해준다.
이 과정이 위에 예제로 나타낸 코드에서 표시한 부분과 같다.
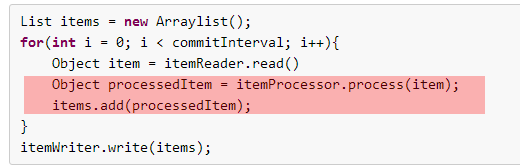
ItemWriter

process를 거쳐 나오면 list형태로 전달 받게 된다. 이 형태를 가지고 Database에 작성하는 부분이라 생각하면 된다.
itemWriter를 상속받고 Ouput Object로 선언한 클래스를 @override된 writer메서드에서 List<? extends Person> items 파라미터로 전달 받는다.
loop 를 돌면서 저장하면 된다.
물론 예제 링크로 알려준 사이트를 참고하면, JPA 특성상 저런 내용을 커스터 마이징한 Writer에 작성하지 않아도 되는 것 같다. (내가 작성할 땐 이해가 부족해서 저렇게 작성하였다.)
JobLauncher
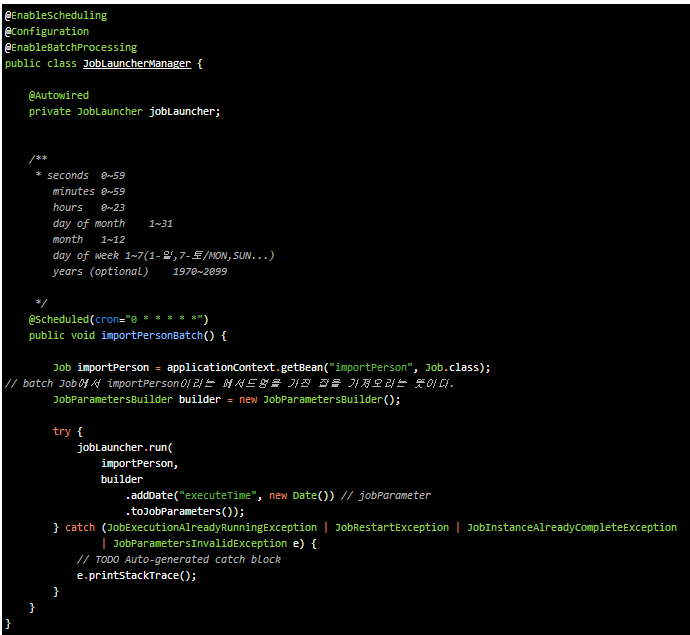
위에 작성된 Batch Process를 실행시키는 부분이다.
@Scheduled를 이용하여 실행 주기를 정의할 수 있다.
참고 및 응용 예제 https://github.com/pkainulainen/spring-batch-examples
스프링 배치 장점
Batch 를 작성한 Step 및 Job 관련된 Table을 제공해주고 각 배치 프로그램이 어떻게 작동해서 어떤 결과가 있었는지 확인 가능하다.
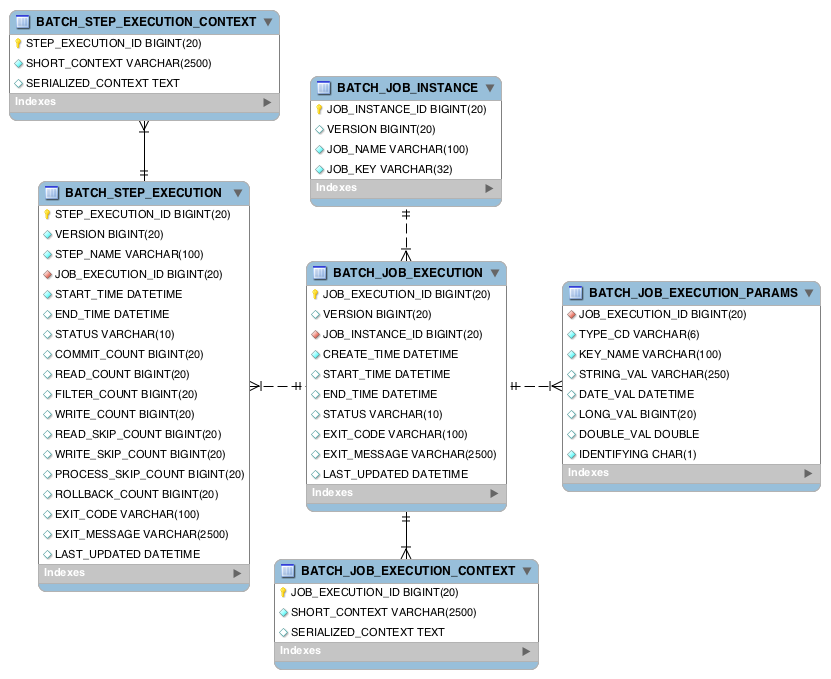
상세 내용은 아래 링크 참조.
http://docs.spring.io/spring-batch/trunk/reference/html/metaDataSchema.html
테이블 컬럼 설명
http://www.egovframe.go.kr/wiki/doku.php?id=egovframework:rte2:brte:batch_core:history_management
각 테이블에 기록된 데이터는 아래와 같다.

BATCH_JOB_INSTANCE

BATCH_JOB_SEQ

BATCH_JOB_EXECUTION_SEQ

BATCH_JOB_EXECUTION

BATCH_JOB_EXECUTION_CONTEXT
BATCH_JOB_EXECUTION_PARAMS

BATCH_STEP_EXECUTION_SEQ

BATCH_STEP_EXECUTION

BATCH_STEP_EXECUTION_CONTEXT
출처 :
http://wiki.gurubee.net/pages/viewpage.action?pageId=4949437
http://docs.spring.io/spring-batch/trunk/reference/html/index.html
http://www.egovframe.go.kr/wiki/doku.php?id=egovframework:rte2:brte:batch_core:step
http://www.egovframe.go.kr/wiki/doku.php?id=egovframework:rte2:brte:batch_core:job
http://docs.spring.io/spring-batch/trunk/reference/html/metaDataSchema.html
- Total
- Today
- Yesterday
- java 폴더구조 구하기
- java 설치
- Database#transaction
- 전자정부프레임워크 tiles
- jstl foreach
- java 특정문자 갯수구하기
- mybatis Merge
- JSTL
- spring property
- JSP 세션
- MyBatis 팁
- POE Excel 만들기
- java 설정
- jstl 커스텀 태그
- Kotlin
- coroutine
- github image 첨부시 주의할점
- java 압축 풀기
- java calendar
- spring ExcelView
- jstl split
- POI EXCEL
- 코루틴
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |